I think most people (even some computer science people, including me) only think of cryptocurrencies anytime when “blockchain” is mentioned. However I recently learned a bit about how git works internally and was very surprised by how similar it is to some of the bitcoin/blockchain concepts introductions that I have studied. So as a note and sharing of this interesting finding, in this article, I’m going to try to explain how git provides its fundamental functionalities, and hopefully if the reader is somewhat familiar with the basic blockchain concepts, can easily see what I claim in the title of the post.
Blockchain knowledge is not required to understand this article, though. I’ll be mostly talking about the git internals. Only basic git knowledge is assumed.
Toy repo setup
I’ll setup a simple git repository for demonstration purposes, all commands in this article will be issued in the repo.
Setup:
1 | # be sure to not be in a repository! |
git under the hood
In essence, git is a key-value data store with abstraction layers built on top of it which can be used by convenient commands. The key corresponding to a piece of data is generated by hashing the data using SHA-1. All information that git needs in order to work is inside the .git directory under the root of every git repository.
There are four types of objects that git hashes and keeps in the data store:
- blobs (binary large objects)
- trees
- commits
- annotated tags
I’ll just go into the initial three of them because they’re enough to paint the picture.
In the toy repo, there exists 7 objects saved after the operations above, including blobs, trees and commits (though you won’t be able to tell the types now). You can view them under .git/objects. The first two characters of the hashes are used as names of the subdirectory and the remaining 38 characters are used as file names (SHA-1 produces a 40-character hexadecimal output).
your hash will not be the same as mine because the input to the hashing function includes username, email, time, etc.
1 | $ tree .git/objects/ |
hash-object and cat-file
git hash-object and git cat-file are two low level commands that directly interacts with objects, they hash and print objects, respectively.
For example we can tell git to hash a string for us:
1 | # --stdin means read from stdin |
use cat-file to see the data with its key(hash):
1 | $ git cat-file -p 45b983b # -p stands for pretty-print |
With these two commands we can manipulate the git data store directly. However, if you print out or open the raw files inside .git/objects, you won’t be able to read them because git compresses them before saving. Also the compressed information includes some metadata, if not cat-file wouldn’t be able to report back the type.
Blobs (Binary Large OBjectS)
Blobs are objects git uses to store contents of files, not including file names, only the file contents. In my local simple repo, hash d28a6d4.. and hash 171edfe.. correspond to the contents of the two text files created. Check it by cat-file:
1 | $ git cat-file -t d28a6d4 |
A blob is like this:
| hash | file content |
|---|---|
| d28a6d4… | FIRST LINE |
Trees
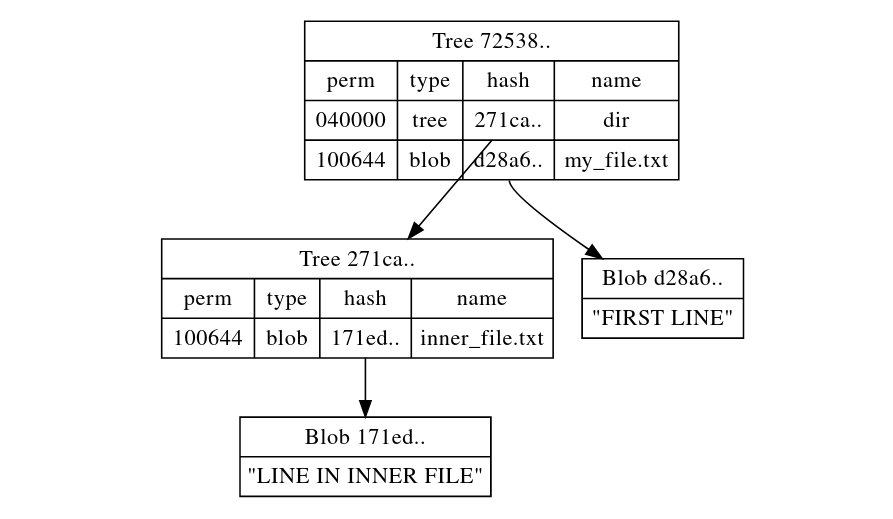
Trees are objects git uses to store contents of directories, each directory is stored as a tree object. It’s easier to understand what’s in a tree by looking at an example:
1 | $ git cat-file -t 72538f3 |
The trees are printed out as tables, looking like this:
| permissions | object type | hash | name |
|---|---|---|---|
| 040000 | tree | 291caa6e2306eca737a3944824676a16fa6a4a39 | dir |
| 100644 | blob | d28a6d4ef745a7bd6e5e0b013ec17ca00b6fbae6 | my_file.txt |
This tree corresponds to the root directory of our toy repository. The interesting thing here is that tree objects can store other tree objects’ information, just like directories(like the ‘dir’ row above). Furthermore, you can see the hash to file name mapping is stored in the tree objects, not in the blob objects.
The meaning of the permissions field is explained in this stackoverflow question.
Here’s some visualization I made :)
commits
Finally, we come to commits.
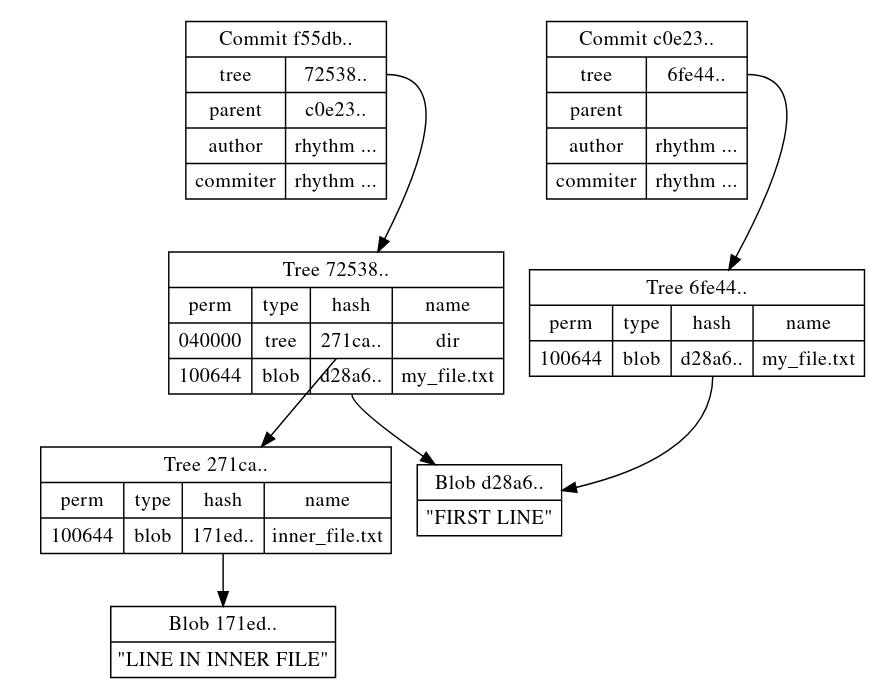
Commits are the last type of objects I’ll be talking about, and they bring the concepts all together. As the name suggests, each commit you do is stored in a commit object by git, they contain a tree, an author, a parent commit (none for the first commit and 2 for merge commits), a commiter, and the commit message. Let’s see it:
1 | $ git cat-file -t c0e23f |
The diagram below shows the structure git uses to keep track of commits and their contents. NOTE that the arrow pointing from commit f55db‘s parent field to commit c0e23 is missing, the reason is that I just can’t get it to work without the graphviz engine making a mess. So you’ll have to imagine for yourself. I hope you get the point though.
Git repos are blockchains
From the explanation above, we can see the git commit data structure is something like this:
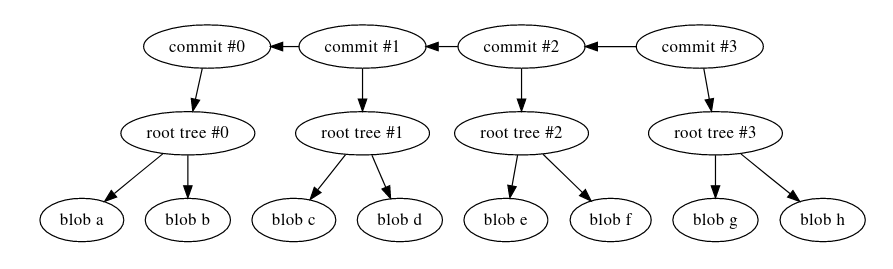
The commits have the following properties:
- acyclic
- hash based back-pointing
- stores the merkle root of the data it corresponds to
- contains timestamp
IMO, these are the properties blockchains possess, but there are voices from both sides, see this SO question and this medium post. As far as I know, the term blockchain isn’t rigorously defined, so there’s no definitive answer.
Acknowledgement
I learned most of the material in this post from the amazing Udemy course taught by Colt Steele. I highly recommend it to people who want to have a solid foundation on git/github.